


こんにちはヤク学長です。
本記事の目的は、「簡単にKaggleを始める」ことを目的としています。
【本記事のもくじ】
まず、「Kaggle」に真剣に取り組むための概要を解説します。
下記の方法で、簡単に概要を抑えることができます。
- 1.3分で学ぶKaggle
- 2.Lesson1基本を学ぼう
- 3.Lesson2:精度向上に向けて
- 4.Lesson3:特徴量エンジニアリング
- 5.Lesson4:パラメータチューニングしてみよう
- 6.Lesson5:検証について
- 7.Lesson6:検証データ作成時の注意
- 8.Lesson7:アンサンブルしてみよう
それでは、上から順番に見ていきます。
なお、本上記の方法を抑えれば成果が出ます。
・Kaggleを使って、必要な基礎スキルをスムーズに身につけ効率的に学ぶための記事です。
記事の内容は「転載 & 引用OK」問題ありません。
- 1 1.3分で学ぶKaggle
- 2 Lesson1基本を学ぼう
- 2.1 ①パッケージの読み込み
- 2.2 ②データの読み込み
- 2.3 head
- 2.4 ③EDA(探索的データ分析)
- 2.5 ④基本統計量を確認する
- 2.6 profiling
- 2.7 pandas-profilingno見方
- 2.8 ⑤各特徴量と目的変数の関係性を確認
- 2.9 ⑤特徴量エンジニアリング
- 2.10 教師データとテストデータを一つに結合する
- 2.11 SEXの値を数値に置き換える
- 2.12 欠損地を補完し、数値に置き換える
- 2.13 Fareの欠損値を平均値で補完する
- 2.14 影響の少なそうな特徴量はいったん削除する
- 2.15 結合したデータを再度、教師データとテストデータに分割
- 2.16 One-Hotエンコーディング
- 2.17 ⑥モデル作成実践
- 2.18 ランダムフォレストアルゴリズムをインポート
- 2.19 教師データの学習
- 2.20 作成したモデルで予測
- 2.21 ⑦Submit
- 2.22 コミットを行う
- 3 Lesson2:精度向上に向けて
- 4 Lesson3:特徴量エンジニアリング
- 5 Lesson4:パラメータチューニングしてみよう
- 6 Lesson5:検証について
- 7 Lesson6:検証データ作成時の注意
- 8 Lesson7:アンサンブルしてみよう
1.3分で学ぶKaggle
Kaggleとは
Kaggleは、機械学習やデータ分析に関するコンペティションやデータセット、コミュニティを提供するオンラインプラットフォームです。Kaggleは、データサイエンティストや機械学習エンジニアが問題解決能力を高め、相互に学び合うことができる場を提供しています。
Kaggleには、様々な種類のコンペティションがあります。参加者は、データセットを分析し、モデルを構築し、最も正確な予測を行うことで賞金を獲得することができます。また、Kaggleでは、データサイエンスに関するチュートリアルやブログ、フォーラムも提供しています。これらのリソースは、機械学習やデータ分析の初心者から上級者まで幅広く活用されています。
Kaggleアカウントを作成方法
Kaggleアカウントを作成するには、以下の手順を実行してください。
- Kaggleのウェブサイトにアクセスしてください。 https://www.kaggle.com/
- Kaggleアカウントを作成するために、”Sign up” ボタンをクリックしてください。
- Kaggleアカウントを作成するためのフォームが表示されます。必要事項を入力してください。フォームには、以下の情報が必要になります。
- ユーザー名
- メールアドレス
- パスワード
- フォームに必要な情報を入力したら、”I understand and accept the terms of service and privacy policy.” チェックボックスを選択してください。
- “Create Account” ボタンをクリックしてください。
- Kaggleから送信される確認メールを確認し、アカウントを有効化してください。
以上の手順を実行することで、Kaggleアカウントを作成することができます。
Kaggleの基本操作
Kaggleを利用するには、以下のような基本的な操作が必要となります。
-
コンペティションの参加
Kaggleには、様々なコンペティションが開催されています。参加するには、コンペティションのページにアクセスし、必要事項を入力して参加してください。コンペティションのページには、データセットや評価指標、ルールなどが掲載されています。 -
ノートブックの作成
Kaggleでは、Jupyter Notebook形式のノートブックを作成することができます。ノートブックは、データ分析やモデルの構築などの作業を行うために利用されます。ノートブックは、Kaggle上で作成することも、自分のコンピューター上で作成してアップロードすることもできます。 -
データセットのダウンロード
Kaggleでは、様々なデータセットが提供されています。データセットをダウンロードするには、該当するデータセットのページにアクセスし、”Download” ボタンをクリックしてください。一部のデータセットは、APIを利用して直接ダウンロードすることもできます。 -
フォーラムの利用
Kaggleでは、コンペティションやデータサイエンスに関する質問や情報共有のためのフォーラムが提供されています。フォーラムにアクセスするには、Kaggleのトップページから”Discussion” を選択してください。 -
チュートリアルやコースの利用
Kaggleでは、データサイエンスや機械学習の基礎から応用までを学ぶことができるチュートリアルやコースが提供されています。これらのリソースは、Kaggleのトップページからアクセスできます。
以上のような基本的な操作が必要となります。Kaggleを使いこなすためには、実際にコンペティションに参加したり、ノートブックを作成したりすることが重要です。
Competition
KaggleのCompetitionとは、データサイエンスや機械学習に関する課題を解決するためのコンペティションのことです。コンペティションは、企業や組織が提供する問題に対して、Kaggleのコミュニティメンバーが解決策を提供するために参加します。
コンペティションには、多くの場合、データセットが提供されます。参加者は、このデータセットを用いてモデルを開発し、最良の予測精度を達成することを目指します。コンペティションは、数週間から数か月にわたって実施され、最終的に最も優れた解決策を提供した参加者には、賞金が与えられることがあります。
Kaggleのコンペティションは、データサイエンスや機械学習の専門家から学生やアマチュアまで、様々な人々が参加することができます。コンペティションは、問題解決能力やアイデアの創造性をテストし、世界中の人々が共同作業を行い、よりよい解決策を見つけるためのプラットフォームを提供しています。
初心者向けコンペ Titanic Machine Learning from Disaster
「Titanic Machine Learning from Disaster」は、Kaggleの初心者向けコンペティションの1つで、タイタニック号の乗客の生存予測モデルを構築することを目的としています。このコンペティションは、データサイエンスや機械学習の基礎を学ぶのに最適なものとされています。
コンペティションには、乗客の情報(性別、年齢、乗船クラス、運賃など)が含まれるトレーニングセットが提供されます。参加者は、このデータセットを使用して、乗客の生存予測モデルを構築し、テストデータセットを使用してモデルの精度を評価します。最終的に、最も正確な予測を行った参加者が勝者となります。
このコンペティションは、初心者にとっては理解しやすい問題設定であり、様々な機械学習アルゴリズムやツールを試すことができます。また、Kaggleのコミュニティ内で意見交換を行いながら、他の参加者のアプローチやソリューションを学ぶことができます。
参加する方法
「Titanic Machine Learning from Disaster」に参加するには、以下の手順を実行してください。
- Kaggleのウェブサイトにアクセスしてください。 https://www.kaggle.com/
- Kaggleにログインするか、アカウントを作成してください。
- “Titanic: Machine Learning from Disaster” コンペティションのページにアクセスしてください。リンクは以下の通りです。 https://www.kaggle.com/c/titanic
- コンペティションページで、”Join Competition” ボタンをクリックしてください。
- Kaggleのページに表示される規約に同意し、参加申請を完了してください。
- トレーニングデータとテストデータが提供されるため、トレーニングデータを使用してモデルを構築し、テストデータを使用してモデルの精度を評価してください。
- 結果を提出するには、KaggleのWebサイト上でフォームに提出する必要があります。
参加するには、Kaggleのアカウントが必要ですが、参加は無料です。また、コンペティションのページには、ノートブックの例やフォーラム、コミュニティなどのリソースが提供されています。これらのリソースを活用して、コンペティションに参加する準備を整えることができます。
モデル作成の流れ
「Titanic Machine Learning from Disaster」などのKaggleコンペティションでのモデル作成の一般的な流れは以下の通りです。
-
データの理解と前処理 トレーニングデータを分析し、欠損値の補完、外れ値の処理、特徴量エンジニアリングなどの前処理を行います。これにより、データをより使いやすい形に変換することができます。
-
モデルの選択 機械学習の手法(回帰、決定木、ランダムフォレスト、ニューラルネットワークなど)から、最適なモデルを選択します。モデルの選択は、データの種類、目的、特徴量の数、予測値の性質などに基づいて行います。
-
モデルのトレーニング 選択したモデルをトレーニングデータに適用し、モデルのパラメータを最適化します。これにより、モデルはトレーニングデータに対して適切な予測を行えるようになります。
-
モデルの評価 モデルのパフォーマンスを評価するために、テストデータを使用してモデルの予測精度を評価します。モデルの性能を最大限に発揮するために、ハイパーパラメータの調整や特徴量の選択などを行うことができます。
-
予測の生成と提出 最終的に、トレーニングデータとテストデータの両方を使用してモデルをトレーニングした後、モデルを使用してテストデータに対する予測を生成します。Kaggleコンペティションの場合、予測結果を提出する必要があります。提出ファイルの形式は、各コンペティションによって異なります。
このように、Kaggleコンペティションでのモデル作成は、データの前処理、モデルの選択、トレーニング、評価、予測結果の提出などのステップで構成されています。
Lesson1基本を学ぼう
①パッケージの読み込み
機械学習やデ②Pythonでよく使用されるパッケージを読み込むことが必要です。以下は、よく使用されるパッケージの読み込み方法の例です。
import numpy as np # 数値計算を行うためのライブラリ
import pandas as pd # データフレームを扱うためのライブラリ
import matplotlib.pyplot as plt # データの可視化を行うためのライブラリ
import seaborn as sns # Matplotlibに基づく高度なデータ可視化ツールに②データの読み込み
データの読み込みには、pandasライブラリを使用することが一般的です。pandasを使用することで、CSV、Excel、SQLデータベースなど、さまざまな形式のデータを読み込むことができます。
以下は、CSV形式のデータを読み込む例です。
# CSVファイルからデータを読み込む
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
出力行数の確認
pandasデータフレームの行数(レコード数)を確認するには、shape属性を使用します。shape属性は、データフレームの行数と列数をタプル形式で返します。
以下は、Titanicデータセットのトレーニングデータに対して、shape属性を使用して行数を確認する例です。
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# 行数の確認
print("トレーニングデータの行数:", train_data.shape[0])
上記のコードでは、train_data.shape[0]を使用して、トレーニングデータの行数を取得し、出力しています。これにより、データセットの規模を把握することができます。
また、len()関数を使用することでも、行数を確認することができます。以下は、同じトレーニングデータに対してlen()関数を使用した例です。
import pandas as pd
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# 行数の確認
print("トレーニングデータの行数:", len(train_data))
どちらの方法でも、pandasデータフレームの行数を確認することができます。
head
pandasデータフレームの先頭の行を確認するには、head()関数を使用します。head()関数は、指定した数の行を先頭から取得し、新しいデータフレームを作成します。
以下は、Titanicデータセットのトレーニングデータに対して、head()関数を使用して先頭の5行を表示する例です。
import pandas as pd
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# 先頭の5行を表示
print(train_data.head())上記のコードでは、train_data.head()を使用して、トレーニングデータの先頭の5行を表示しています。引数に数値を指定することで、取得する行数を変更することもできます。例えば、train_data.head(10)とすると、先頭の10行を表示することができます。
head()関数は、データフレームの先頭を確認するのに便利な関数です。データフレームが大きな場合でも、先頭の行を確認することで、データの概要を把握することができます。
③EDA(探索的データ分析)
Titanicデータセットを使用して、簡単なEDA(探索的データ分析)を行うためのコードの例です。
# データの結合
data = pd.concat([train_data, test_data], sort=False)
# データの基本統計量の計算
print(data.describe())
# データの欠損値の確認
print(data.isnull().sum())
# ヒストグラムの作成
data.hist(figsize=(10, 10))
plt.show()
# 相関係数行列の作成
corr_matrix = data.corr()
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
plt.show()
# 生存者と死亡者の数の比較
sns.countplot(x='Survived', data=train_data)
plt.show()
# 男女の生存率の比較
sns.barplot(x='Sex', y='Survived', data=train_data)
plt.show()
# チケットクラスごとの生存率の比較
sns.barplot(x='Pclass', y='Survived', data=train_data)
plt.show()
上記のコードでは、以下のようなEDAの手順を行っています。
- データの読み込み
- データの結合
- データの基本統計量の計算
- データの欠損値の確認
- データの可視化
最後に、ヒストグラム、相関係数行列、生存者と死亡者の数の比較、男女の生存率の比較、チケットクラスごとの生存率の比較など、いくつかのグラフを作成しています。これらのグラフを使用することで、データの特徴や傾向をより詳しく分析することができます。
④基本統計量を確認する
describe
pandasデータフレームの基本統計量を確認するには、describe()関数を使用します。describe()関数は、各数値変数の基本統計量(件数、平均、標準偏差、最小値、四分位数、最大値)をまとめて表示します。
以下は、Titanicデータセットのトレーニングデータに対して、describe()関数を使用して基本統計量を表示する例です。
import pandas as pd
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# 基本統計量の表示
print(train_data.describe())上記のコードでは、train_data.describe()を使用して、トレーニングデータの基本統計量を表示しています。出力結果には、各数値変数の基本統計量が表示されます。
describe()関数は、データフレームの基本統計量を確認するのに便利な関数です。データフレームの各数値変数について、どのような範囲に分布しているか、またどのような外れ値が存在するかなどを確認することができます。
profiling
pandas-profilingライブラリを使用すると、pandasデータフレームに対する詳細なプロファイルを簡単に作成することができます。プロファイルには、欠損値の数、変数の種類、相関関係、分位数、ヒストグラム、散布図などの情報が含まれます。
以下は、pandas-profilingライブラリを使用してTitanicデータセットのトレーニングデータに対するプロファイルを作成する例です。
import pandas as pd
import pandas_profiling
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# プロファイルの作成
profile = pandas_profiling.ProfileReport(train_data)
profile.to_file(output_file="output.html")
上記のコードでは、pandas-profilingライブラリのProfileReport()関数を使用して、トレーニングデータのプロファイルを作成しています。to_file()メソッドを使用して、作成したプロファイルをHTMLファイルとして保存しています。
プロファイルを作成することで、データセットの詳細な分析を行うことができます。また、欠損値の数や変数の種類などの情報を把握することで、データの前処理や特徴量エンジニアリングのためのアイデアを得ることができます。
pandas-profilingno見方
pandas-profilingライブラリを使用して作成したプロファイルには、データセットに関する詳細な情報が含まれています。以下に、pandas-profilingで生成されたHTMLレポートの主なセクションについて説明します。
- Overview
概要セクションには、データセット全体に関する概要が含まれます。データセットの行数、列数、欠損値の数、重複した行の数などが表示されます。
- Variables
変数セクションには、データセット内の各変数に関する詳細な情報が含まれます。各変数の種類、欠損値の数、一意の値の数、最頻値、平均値、標準偏差、最小値、最大値、四分位数などが表示されます。また、カテゴリ変数の場合は、各カテゴリ値の出現頻度と割合が表示されます。
- Correlations
相関セクションには、データセット内の変数間の相関関係に関する情報が含まれます。相関係数とともに、ヒートマップとして可視化されています。
- Missing values
欠損値セクションには、各変数の欠損値の数と割合が表示されます。また、欠損値のある行の数と割合も表示されます。
- Sample
サンプルセクションには、データセット内の先頭と末尾の行が表示されます。これにより、データセットの形式と内容を簡単に確認することができます。
- Warnings
警告セクションには、データセット内の問題が警告として表示されます。たとえば、カテゴリ変数が多すぎる場合や、特定の変数に欠損値が多すぎる場合などが警告として表示されます。
pandas-profilingによるレポートは、データセットの詳細な分析を容易にするために設計されています。これにより、データセットに関する深い理解を得ることができます。
⑤各特徴量と目的変数の関係性を確認
各特徴量と目的変数の関係性を確認するには、データの可視化が有効です。以下は、Titanicデータセットのトレーニングデータに対して、各特徴量と目的変数(Survived)の関係性を可視化するための例です。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# チケットクラスごとの生存率の比較
sns.barplot(x='Pclass', y='Survived', data=train_data)
plt.show()
# 男女の生存率の比較
sns.barplot(x='Sex', y='Survived', data=train_data)
plt.show()
# 年齢と生存率の関係
sns.histplot(x='Age', hue='Survived', data=train_data, kde=True)
plt.show()
# 乗船した港と生存率の比較
sns.barplot(x='Embarked', y='Survived', data=train_data)
plt.show()
# 同乗していた兄弟/配偶者の数と生存率の関係
sns.barplot(x='SibSp', y='Survived', data=train_data)
plt.show()
# 同乗していた親/子供の数と生存率の関係
sns.barplot(x='Parch', y='Survived', data=train_data)
plt.show()
上記のコードでは、seabornライブラリを使用して、各特徴量と目的変数の関係性を可視化するためのグラフを作成しています。各グラフには、横軸に特徴量、縦軸に生存率を設定しています。各特徴量ごとに、目的変数との関係性を確認することができます。
例えば、sns.barplot(x='Pclass', y='Survived', data=train_data)は、チケットクラスと生存率の関係性を可視化するグラフです。このグラフから、チケットクラスが高いほど生存率が高いことがわかります。
これらのグラフを使用することで、各特徴量と目的変数の関係性を詳しく分析することができます。
ヒストグラム
ヒストグラムは、データの分布を可視化するためのグラフの一種です。データを等間隔の幅で区切り、各区間に含まれるデータの個数を縦軸にプロットします。ヒストグラムは、特に数値データの分布を可視化する際によく使われます。
以下は、Titanicデータセットのトレーニングデータに対して、年齢(Age)のヒストグラムを作成するための例です。
import pandas as pd
import matplotlib.pyplot as plt
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# ヒストグラムの作成
plt.hist(train_data['Age'], bins=20)
plt.xlabel('Age')
plt.ylabel('Count')
plt.show()
上記のコードでは、plt.hist()関数を使用して、年齢のヒストグラムを作成しています。bins引数を使用して、区間の数を指定することができます。横軸に年齢、縦軸にデータの個数を設定しています。
このように、ヒストグラムを使用することで、データの分布を簡単に把握することができます。また、データの分布に特徴がある場合、分布の形状から特徴を把握することもできます。
⑤特徴量エンジニアリング
特徴量エンジニアリングは、機械学習のタスクで使用する特徴量を選択・作成するプロセスです。特徴量エンジニアリングにより、モデルの精度を向上させることができます。以下に、特徴量エンジニアリングの一例を示します。
- 欠損値の処理
欠損値がある場合は、欠損値を埋めたり、欠損値が含まれる行を削除したりすることが必要です。欠損値を埋める方法には、平均値や中央値、最頻値などの統計量で埋める方法や、欠損値を予測するモデルを使用する方法などがあります。
- カテゴリ変数の処理
カテゴリ変数は、モデルに入力することができないため、数値変換する必要があります。変換方法には、One-hotエンコーディングやLabel Encodingなどがあります。また、カテゴリ変数同士の関係性を表す新しい特徴量を作成することもできます。
- 特徴量のスケーリング
特徴量の値が異なる場合、モデルの精度に影響を与えることがあります。スケーリングを行うことで、特徴量の値を正規化することができます。代表的なスケーリング方法には、標準化や正規化があります。
- 新しい特徴量の作成
元の特徴量から、新しい特徴量を作成することで、モデルの精度を向上させることができます。新しい特徴量の作成には、ドメイン知識を活用して意味のある特徴量を作成する方法や、特徴量同士の演算を行う方法があります。
特徴量エンジニアリングによって、モデルの精度を向上させることができます。データに対する理解を深め、特徴量を適切に処理することが重要です。
教師データとテストデータを一つに結合する
教師データとテストデータに対して、双方に特徴量エンジニアリングを行う場合、それぞれに対して処理を行った後、再度二つのデータを結合する必要があります。以下は、Titanicデータセットの教師データとテストデータに対して、特徴量エンジニアリングを行い、再度二つのデータを結合するための例です。
import pandas as pd
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
test_data = pd.read_csv('../input/titanic/test.csv')
# 教師データとテストデータを結合する
all_data = pd.concat([train_data, test_data], sort=False)
# 欠損値の処理
all_data['Age'].fillna(all_data['Age'].median(), inplace=True)
all_data['Fare'].fillna(all_data['Fare'].median(), inplace=True)
all_data['Embarked'].fillna(all_data['Embarked'].mode()[0], inplace=True)
# カテゴリ変数の処理
all_data = pd.get_dummies(all_data, columns=['Sex', 'Embarked'])
# 新しい特徴量の作成
all_data['FamilySize'] = all_data['SibSp'] + all_data['Parch'] + 1
all_data['IsAlone'] = 0
all_data.loc[all_data['FamilySize'] == 1, 'IsAlone'] = 1
# スケーリング
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
all_data['Age_scaled'] = scaler.fit_transform(all_data['Age'].values.reshape(-1, 1))
all_data['Fare_scaled'] = scaler.fit_transform(all_data['Fare'].values.reshape(-1, 1))
# 再度教師データとテストデータに分割する
train_data = all_data[:len(train_data)]
test_data = all_data[len(train_data):]
上記のコードでは、まず教師データとテストデータを結合した後、特徴量エンジニアリングを行っています。concat関数を使用して、二つのデータを結合しています。次に、欠損値の処理、カテゴリ変数の処理、新しい特徴量の作成、スケーリングの処理を行っています。最後に、再度教師データとテストデータに分割しています。
このように、教師データとテストデータに対して、特徴量エンジニアリングを行う場合は、それぞれに対して処理を行い、再度二つのデータを結合することが必要です。
SEXの値を数値に置き換える
TitanicデータセットのSex列は、文字列でMaleまたはFemaleの値を持ちます。このままでは機械学習モデルに入力することができません。文字列を数値に置き換える必要があります。以下は、Sex列を数値に置き換えるための例です。
import pandas as pd
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# Sex列の値を数値に置き換える
train_data['Sex'] = train_data['Sex'].map({'male': 0, 'female': 1})
# 結果の確認
print(train_data['Sex'].head())
上記のコードでは、map()関数を使用して、Sex列の値を数値に置き換えています。map()関数の引数には、置換前の文字列をキー、置換後の値をバリューとする辞書を指定しています。男性を表す’male’を0、女性を表す’female’を1に置き換えています。
Sex列を数値に置き換えることで、機械学習モデルに入力することができるようになります。
欠損地を補完し、数値に置き換える
欠損値の補完と数値の置き換えには、いくつかの方法があります。代表的な方法には、平均値、中央値、最頻値で補完する方法や、回帰モデルを使用して欠損値を予測する方法があります。以下は、TitanicデータセットのAge列を中央値で補完し、Embarked列の欠損値を最頻値で補完し、数値に置き換えるための例です。
import pandas as pd
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# Age列の欠損値を中央値で補完する
train_data['Age'].fillna(train_data['Age'].median(), inplace=True)
# Embarked列の欠損値を最頻値で補完する
train_data['Embarked'].fillna(train_data['Embarked'].mode()[0], inplace=True)
# Embarked列の値を数値に置き換える
train_data['Embarked'] = train_data['Embarked'].map({'S': 0, 'C': 1, 'Q': 2})
# 結果の確認
print(train_data[['Age', 'Embarked']].head())上記のコードでは、fillna()関数を使用して、Age列の欠損値を中央値で、Embarked列の欠損値を最頻値で補完しています。次に、Embarked列の値を数値に置き換えています。map()関数を使用して、’S’を0、’C’を1、’Q’を2に置き換えています。
欠損値を補完し、数値に置き換えることで、機械学習モデルに入力することができるようになります。ただし、補完方法や置き換え方法は、データの性質や背景に応じて適切に選択する必要があります。
Fareの欠損値を平均値で補完する
import pandas as pd
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# Fare列の欠損値を平均値で補完する
train_data['Fare'].fillna(train_data['Fare'].mean(), inplace=True)
# 結果の確認
print(train_data['Fare'].head())上記のコードでは、fillna()関数を使用して、Fare列の欠損値を平均値で補完しています。mean()関数を使用して、Fare列の平均値を計算し、それを欠損値に代入しています。
欠損値を平均値で補完することで、機械学習モデルに入力することができるようになります。ただし、補完方法はデータの性質や背景に応じて適切に選択する必要があります。
影響の少なそうな特徴量はいったん削除する
import pandas as pd
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# 影響の少なそうな特徴量を削除する
train_data.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 結果の確認
print(train_data.head())
上記のコードでは、drop()関数を使用して、PassengerId、Name、Ticket、Cabinの4つの特徴量を削除しています。axis=1を指定することで、列方向に削除することを指定しています。また、inplace=Trueを指定することで、元のDataFrameを変更しています。
影響の少なそうな特徴量を削除することで、モデルの複雑さを減らし、過学習を防ぐことができます。ただし、削除する特徴量の選択はデータの性質や背景に応じて適切に選択する必要があります。
結合したデータを再度、教師データとテストデータに分割
教師データとテストデータに分割するには、結合したデータを分割する必要があります。以下は、Titanicデータセットの教師データとテストデータに分割するための例です。
# 再度教師データとテストデータに分割する
train_data = all_data[:len(train_data)]
test_data = all_data[len(train_data):]
# 結果の確認
print(train_data.shape)
print(test_data.shape)
上記のコードでは、concat()関数を使用して教師データとテストデータを結合した後、必要な前処理を行っています。最後に、len()関数を使用して教師データのレコード数を取得し、[]演算子を使用して、結合したデータを教師データとテストデータに分割しています。また、結果を出力して、教師データとテストデータのレコード数を確認しています。
このように、教師データとテストデータに分割するために、結合したデータを分割する必要があります。
One-Hotエンコーディング
One-Hotエンコーディングは、カテゴリカル変数を数値データに変換する方法の一つで、各カテゴリ値を新しい特徴量として表現する方法です。以下は、TitanicデータセットのEmbarked列に対してOne-Hotエンコーディングを行うための例です。
import pandas as pd
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# Embarked列をOne-Hotエンコーディングする
embarked_one_hot = pd.get_dummies(train_data['Embarked'], prefix='Embarked')
# 元のデータと結合する
train_data = pd.concat([train_data, embarked_one_hot], axis=1)
# 不要な列を削除する
train_data.drop(['Embarked'], axis=1, inplace=True)
# 結果の確認
print(train_data.head())上記のコードでは、get_dummies()関数を使用してEmbarked列をOne-Hotエンコーディングしています。prefix引数を使用して、新しい特徴量の名前に’Embarked’の接頭辞を付けています。次に、concat()関数を使用して、元のデータにOne-Hotエンコーディングした特徴量を結合しています。最後に、不要なEmbarked列を削除しています。
One-Hotエンコーディングは、カテゴリカル変数を数値データに変換する方法の一つで、機械学習モデルに入力することができます。ただし、カテゴリカル変数の数が多い場合、One-Hotエンコーディングを行うことでデータの次元数が増加し、計算量が増大する可能性があります。
⑥モデル作成実践
アルゴリズムに投入するため特徴量と目的変数を分離
import pandas as pd
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# 不要な列を削除する
train_data.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 目的変数と特徴量を分離する
y = train_data['Survived']
X = train_data.drop(['Survived'], axis=1)
# 結果の確認
print(y.head())
print(X.head())上記のコードでは、drop()関数を使用して不要な列を削除しています。次に、drop()関数を使用して目的変数であるSurvived列をyに分離し、drop()関数を使用してSurvived列を削除して特徴量のDataFrameをXに分離しています。
特徴量と目的変数を分離することで、機械学習アルゴリズムに入力するためのデータを作成することができます。また、目的変数と特徴量の分離によって、データの前処理や特徴量エンジニアリングの際に、目的変数を誤って変換してしまうなどのミスを防ぐことができます。
ランダムフォレストアルゴリズムをインポート
ランダムフォレストアルゴリズムをインポートするには、Scikit-learnライブラリを使用します。以下は、Scikit-learnライブラリからランダムフォレストアルゴリズムをインポートするための例です。
from sklearn.ensemble import RandomForestClassifier
# インスタンスを作成する clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)RandomForestClassifierクラスのn_estimators引数を100、max_depth引数を2、random_state引数を0に設定して、ランダムフォレストアルゴリズムのインスタンスを作成しています。n_estimatorsは、ランダムフォレスト内で作成する決定木の数を指定するパラメータであり、max_depthは、作成する決定木の深さを指定するパラメータです。また、random_stateは、ランダムな値を生成する際に使用するシード値を指定するパラメータです。ランダムフォレストアルゴリズムを使用する際は、適切なパラメータの設定が重要です。n_estimatorsやmax_depthなどのパラメータは、データの性質や背景に応じて適切に設定する必要があります。
教師データの学習
ランダムフォレストアルゴリズムを使用して、教師データの学習を行うためには、fit()メソッドを使用します。以下は、ランダムフォレストアルゴリズムを使用して、Titanicデータセットの教師データを学習するための例です。
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
# 不要な列を削除する
train_data.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 目的変数と特徴量を分離する
y = train_data['Survived']
X = train_data.drop(['Survived'], axis=1)
# ランダムフォレストアルゴリズムのインスタンスを作成する
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)
# 教師データで学習する
clf.fit(X, y)
上記のコードでは、fit()メソッドを使用して、Xとyを引数として、ランダムフォレストアルゴリズムによる教師データの学習を行っています。ランダムフォレストアルゴリズムは、決定木を多数集約したアンサンブル学習の一つであり、複数の決定木を作成して、投票によって最終的な予測を決定します。
ランダムフォレストアルゴリズムは、パラメータの設定によって性能が大きく変わるアルゴリズムの一つです。適切なパラメータを設定することで、高い予測性能を発揮することができます。
作成したモデルで予測
predict()メソッドを使用します。以下は、ランダムフォレストアルゴリズムによる学習済みモデルを使用して、Titanicデータセットのテストデータの予測を行うための例です。import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
test_data = pd.read_csv('../input/titanic/test.csv')
# 不要な列を削除する
train_data.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
test_data.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 目的変数と特徴量を分離する
y_train = train_data['Survived']
X_train = train_data.drop(['Survived'], axis=1)
# ランダムフォレストアルゴリズムのインスタンスを作成する
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)
# 教師データで学習する
clf.fit(X_train, y_train)
# テストデータの予測を行う
X_test = test_data.copy()
y_pred = clf.predict(X_test)
predict()メソッドを使用して、テストデータの予測を行っています。copy()メソッドを使用して、テストデータのDataFrameのコピーを作成しています。ランダムフォレストアルゴリズムは、学習済みのモデルを使用して、テストデータの各サンプルに対する生存予測のクラスを予測します。予測された生存クラスは、モデルの性能を評価するために使用できます。ただし、テストデータには正解が含まれていないため、予測性能の正確な評価はできません。したがって、モデルの評価を行うためには、交差検証などの評価手法を使用する必要があります。
⑦Submit
gender_submission.csvファイルと同じ形式のファイルを作成し、KaggleのWebページから提出する必要があります。以下は、ランダムフォレストアルゴリズムによって予測された生存クラスを、gender_submission.csvファイルと同じ形式のファイルに保存するための例です。import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# CSVファイルからデータを読み込む
train_data = pd.read_csv('../input/titanic/train.csv')
test_data = pd.read_csv('../input/titanic/test.csv')
gender_submission_data = pd.read_csv('../input/titanic/gender_submission.csv')
# 不要な列を削除する
train_data.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
test_data.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 目的変数と特徴量を分離する
y_train = train_data['Survived']
X_train = train_data.drop(['Survived'], axis=1)
# ランダムフォレストアルゴリズムのインスタンスを作成する
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)
# 教師データで学習する
clf.fit(X_train, y_train)
# テストデータの予測を行う
X_test = test_data.copy()
y_pred = clf.predict(X_test)
# 提出ファイルを作成する
submission = pd.DataFrame({
'PassengerId': test_data['PassengerId'],
'Survived': y_pred
})
# 提出ファイルをCSVファイルに書き出す
submission.to_csv('submission.csv', index=False)
上記のコードでは、予測された生存クラスをsubmission.csvファイルに書き出しています。to_csv()メソッドを使用して、DataFrameをCSVファイルに書き出すことができます。提出ファイルが完成したら、KaggleのWebページから提出することができます。
コミットを行う
KaggleのNotebookでコミットを行うには、以下の手順を実行します。
- ノートブックの右上にある「Save Version」ボタンをクリックします。
- 「Describe your changes(変更内容を説明する)」という欄に、コミットの内容を記述します。
- 「Save」ボタンをクリックして、コミットを保存します。
コミットを保存すると、KaggleのNotebookに新しいバージョンが作成されます。他のユーザーは、異なるバージョンを見ることができます。また、異なるバージョンを比較することもできます。Notebookを改善するためのフィードバックを受けることができます。
Lesson2:精度向上に向けて
精度向上に向けて、以下のようなことが考えられます。
-
特徴量の選択や作成 特徴量の質が予測性能に大きく影響するため、適切な特徴量の選択や作成が必要です。特徴量の選択や作成には、データの理解やドメイン知識が必要となる場合があります。
-
ハイパーパラメータのチューニング ランダムフォレストアルゴリズムには、複数のハイパーパラメータがあります。適切なハイパーパラメータの設定によって、予測性能を向上させることができます。
-
アンサンブル学習 複数のモデルを組み合わせてアンサンブル学習を行うことで、予測性能を向上させることができます。例えば、ランダムフォレストアルゴリズムと勾配ブースティングアルゴリズムを組み合わせてアンサンブル学習を行うことができます。
-
データの前処理 データの前処理によって、予測性能を向上させることができます。例えば、外れ値の処理や欠損値の補完、正規化などが考えられます。
-
モデルの変更 ランダムフォレストアルゴリズム以外のモデルを使用することで、予測性能を向上させることができます。例えば、サポートベクターマシンやニューラルネットワークなどのモデルが考えられます。
以上のような方法を試して、予測性能を向上させることができます。ただし、過学習に陥ることに注意が必要です。過学習を防ぐために、交差検証や正則化などの方法を使用することが推奨されます。
アルゴリズムチートシート
機械学習アルゴリズムを選択するためのチートシートを紹介します。以下のチートシートは、Scikit-learnライブラリに含まれるアルゴリズムを対象にしています。
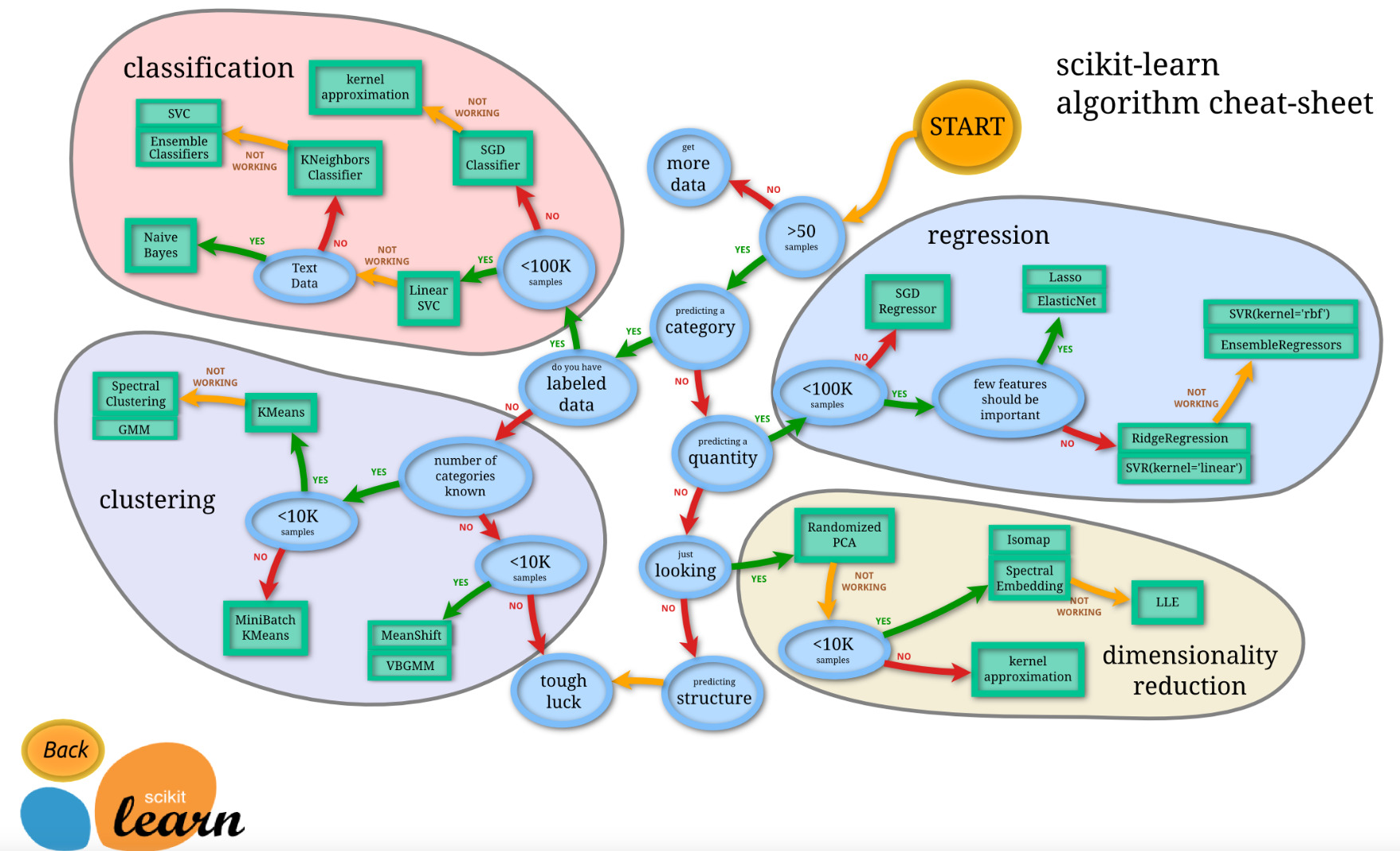
このチートシートは、Scikit-learnライブラリに含まれるアルゴリズムを、データのタイプや特徴量の数、サンプルの数、予測対象などの特徴に基づいてグループ化しています。選択したアルゴリズムが実装可能かどうか、またどのような問題に適しているかを確認するために、使用するデータと目的に適したアルゴリズムを選択することが重要です。ただし、このチートシートはあくまでも一般的なガイドラインであり、最終的なアルゴリズムの選択は、問題の性質やデータの性質に応じて変更する必要がある場合があります。
ロジスティック回帰を実装しよう
ロジスティック回帰は、分類問題に使用される線形モデルの一種です。以下の手順に従って、Pythonでロジスティック回帰を実装してみましょう。
- 必要なライブラリをインポートする
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
- データを読み込む
df = pd.read_csv('data.csv')- 特徴量と目的変数を分離する
X = df.drop('target', axis=1)
y = df['target']
- データをトレーニングセットとテストセットに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)- ロジスティック回帰のインスタンスを作成する
clf = LogisticRegression()- トレーニングデータでモデルを学習する
clf.fit(X_train, y_train)- テストデータで予測を行い、精度を計算する
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
以上の手順で、ロジスティック回帰を実装することができます。ただし、実際の問題に対して適切なハイパーパラメータの調整や特徴量の選択、データの前処理などが必要になる場合があります。
Kaggleはどうやって順位が決まるのか
Kaggleのコンペティションにおける順位は、評価指標に基づいて決定されます。コンペティションによって異なる評価指標がありますが、一般的には予測値と実際の値の誤差を最小化することが求められます。評価指標が最小化を求める場合は、スコアが小さい方が高い順位となります。一方、評価指標が最大化を求める場合は、スコアが大きい方が高い順位となります。
Kaggleでは、コンペティションの結果を提出するためのサンプルファイルが提供されます。参加者は、このサンプルファイルに予測値を記入して提出し、Kaggleの評価システムによってスコアが計算されます。スコアが高い順にランキングされ、上位にランクインした参加者には賞金が与えられることがあります。
ただし、Kaggleのコンペティションは、実際の問題に直結するものが多く、評価指標が単純なものではない場合もあります。そのため、参加者は適切な評価指標を理解し、最適なモデルを構築するために試行錯誤する必要があります。
Lesson3:特徴量エンジニアリング
特徴量エンジニアリングとは、機械学習において、モデルの予測性能を向上させるために、データから特徴量を生成・変換することを指します。データセットに含まれる特徴量が、モデルの性能に直結するため、特徴量エンジニアリングは機械学習の重要なステップの一つです。
以下は、特徴量エンジニアリングの代表的な手法です。
-
欠損値の処理
- 欠損値がある場合、平均値や中央値で補完する、または欠損値が多い場合は特徴量自体を削除するなどの方法があります。
-
カテゴリ変数のエンコーディング
- カテゴリ変数を数値化する方法として、One-Hotエンコーディングやラベルエンコーディングなどがあります。
-
スケーリング
- 特徴量の値の範囲を揃えるために、正規化や標準化を行うことがあります。
-
特徴量の生成
- 既存の特徴量から新たな特徴量を生成する方法として、多項式特徴量や交互作用特徴量などがあります。
-
データの分割
- 時系列データなど、データの時間的な変化を考慮する場合、データを一定期間ごとに分割することがあります。
-
外れ値の処理
- 外れ値がある場合、外れ値を除去する、または異常値として特別に扱うなどの方法があります。
特徴量エンジニアリングには、データに対する理解やドメイン知識が必要になる場合があります。また、様々な手法を試し、最適な特徴量エンジニアリングの方法を見つけるために、試行錯誤を繰り返すことが必要になる場合があります。
新たな特徴量を作る
Titanicデータセットでは、既存の特徴量から新たな特徴量を生成することでモデルの精度を向上させることができます。以下に、Titanicデータセットから新たな特徴量を作成する方法の一例を示します。
-
FamilySize(家族の人数)特徴量の作成
SibSp(兄弟姉妹・配偶者の数)とParch(両親・子供の数)から、家族の人数を計算する特徴量を作成します。
train_data['FamilySize'] = train_data['SibSp'] + train_data['Parch'] + 1
test_data['FamilySize'] = test_data['SibSp'] + test_data['Parch'] + 1
- IsAlone(一人で旅行しているかどうか)特徴量の作成
FamilySizeが1の場合は、一人で旅行しているということになります。
train_data['IsAlone'] = np.where(train_data['FamilySize'] == 1, 1, 0)
test_data['IsAlone'] = np.where(test_data['FamilySize'] == 1, 1, 0)
- NameLength(名前の長さ)特徴量の作成
Name列の文字数から、名前の長さを表す特徴量を作成します。
train_data['NameLength'] = train_data['Name'].apply(len)
test_data['NameLength'] = test_data['Name'].apply(len)- Title(敬称)特徴量の作成
Name列から、敬称を表す特徴量を抽出します。
train_data['Title'] = train_data['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
test_data['Title'] = test_data['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
- AgeGroup(年齢層)特徴量の作成
Age列の値を幾つかの範囲に分け、年齢層を表す特徴量を作成します。
train_data['AgeGroup'] = pd.cut(train_data['Age'], bins=[0, 10, 20, 30, 40, 50, 60, 70, 80])
test_data['AgeGroup'] = pd.cut(test_data['Age'], bins=[0, 10, 20, 30, 40, 50, 60, 70, 80])
以上のように、既存の特徴量から新たな特徴量を生成することで、モデルの精度向上に繋がる可能性があります。ただし、特徴量の生成にはドメイン知識や試行錯誤が必要になる場合があります。
平均や標準偏差、ランダムな要素を加える
Titanicデータセットから新たな特徴量を作成する方法の一例として、平均や標準偏差、ランダムな要素を加えた特徴量の作成方法を以下に示します。
-
平均や標準偏差を用いた特徴量
年齢や運賃などの数値型の特徴量について、平均や標準偏差などの統計量を算出し、新たな特徴量を作成することができます。
# 年齢の平均値に対する乗算を行った特徴量
train_data['AgeMeanMultiplier'] = train_data['Age'] / train_data['Age'].mean()
test_data['AgeMeanMultiplier'] = test_data['Age'] / test_data['Age'].mean()
# 運賃の標準偏差に対する乗算を行った特徴量
train_data['FareStdMultiplier'] = train_data['Fare'] / train_data['Fare'].std()
test_data['FareStdMultiplier'] = test_data['Fare'] / test_data['Fare'].std()
- ランダムな要素を加えた特徴量
特定のパターンには当てはまらないランダムな要素を加えることで、モデルの汎化性能を向上させることができます。
# 0から1までの範囲でランダムな値を生成する特徴量
train_data['RandomFeature'] = np.random.rand(len(train_data))
test_data['RandomFeature'] = np.random.rand(len(test_data))
以上のように、平均や標準偏差、ランダムな要素を加えた特徴量を作成することで、モデルの精度向上に繋がる可能性があります。ただし、特徴量の生成にはドメイン知識や試行錯誤が必要になる場合があります。
LightGBM
LightGBMは、勾配ブースティング決定木をベースにした高速な勾配ブースティングフレームワークです。LightGBMは、大規模なデータセットや高次元データに対しても高速に動作することが特徴です。また、カテゴリ変数や欠損値の扱いにも優れています。
以下は、LightGBMを使用してモデルを構築する手順の一例です。
-
ライブラリのインストール
LightGBMを使用するには、まずライブラリをインストールする必要があります。以下のコマンドを使用して、ライブラリをインストールします。
pip install lightgbm- データの準備
モデルを構築するためには、データを準備する必要があります。Pandasを使用してデータを読み込み、特徴量と目的変数を分離します。
import pandas as pd
# データの読み込み
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
# 特徴量と目的変数の分離
X_train = train_data.drop(['Survived'], axis=1)
y_train = train_data['Survived']
X_test = test_data- カテゴリ変数の処理
LightGBMは、カテゴリ変数を数値型に変換する必要がありません。そのため、カテゴリ変数をそのまま扱うことができます。以下は、カテゴリ変数を指定した場合の例です。
import lightgbm as lgb
# カテゴリ変数を指定した場合の例
categorical_features = ['Sex', 'Embarked']
train_data = lgb.Dataset(X_train, label=y_train, categorical_feature=categorical_features)
- モデルの構築
LightGBMでは、LightGBMクラスを使用してモデルを構築します。以下は、LightGBMクラスを使用してモデルを構築する例です。
# モデルの構築
params = {
'objective': 'binary',
'boosting_type': 'gbdt',
'metric': 'binary_logloss',
'num_leaves': 31,
'learning_rate': 0.05,
}
model = lgb.train(params, train_data, num_boost_round=100)
-
予測の実行
モデルを構築したら、テストデータを用いて予測を実行します。以下は、LightGBMを使用した予測の実行例です。
# 予測の実行
y_pred = model.predict(X_test)
# 予測結果を0または1に変換する
y_pred[y_pred >= 0.5] = 1
y_pred[y_pred < 0.5] = 0
# 提出用ファイルの作成
submission = pd.DataFrame({'PassengerId': test_data['PassengerId'], 'Survived': y_pred})
submission.to_csv('submission.csv', index=False)このように、予測結果を0または1に変換し、提出用のCSVファイルを作成します。LightGBMを使用した予測の場合、パフォーマンスを向上させるために、ハイパーパラメータの調整や特徴量エンジニアリングなどを行う必要があります。
過学習
過学習(overfitting)とは、モデルが訓練データに対して過度に適合し、汎化性能が低下する現象のことを指します。過学習が発生すると、訓練データには良い性能を発揮するが、未知のデータに対しては性能が低下するため、モデルの予測性能が低下する可能性があります。
過学習は、以下のような理由で発生することがあります。
- モデルが複雑すぎる
- データがノイズを含んでいる
- 訓練データが少ない
過学習を防ぐためには、以下のような手法があります。
- モデルの複雑さを抑える(例えば、決定木の深さを浅くする)
- データの前処理を適切に行う(例えば、ノイズを除去する)
- データの水増しを行う(例えば、データ拡張による画像の回転や拡大縮小)
- モデルの正則化を行う(例えば、L1正則化やL2正則化)
- 交差検証によるハイパーパラメータのチューニング
過学習が発生しているかどうかを判断するには、以下のような方法があります。
- 訓練データと検証データの誤差を比較する
- 学習曲線を描画して、過学習の兆候を探す
- 正則化の強さを変えた場合のモデルの性能変化を見る
過学習が発生している場合は、上記の手法を用いて対処することが重要です。
tain test split
トレーニングデータとテストデータの分割(train-test split)とは、機械学習モデルの評価を行うために、データをトレーニング用とテスト用に分割する処理のことを指します。
トレーニングデータとは、機械学習モデルを学習するために使用するデータのことであり、モデルのパラメータを決定するために利用されます。一方、テストデータとは、学習済みのモデルの性能を評価するために使用するデータのことであり、未知のデータに対する予測精度を評価するために利用されます。
トレーニングデータとテストデータの分割は、以下のような手順で行います。
-
データの準備
- 機械学習モデルをトレーニングするためのデータを用意します。データは、特徴量と目的変数を含んだデータフレーム形式で用意します。
-
データの分割
- データをトレーニングデータとテストデータに分割します。一般的に、トレーニングデータの割合を70〜80%、テストデータの割合を20〜30%に設定します。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
モデルの学習と評価
- トレーニングデータを用いてモデルを学習し、テストデータを用いてモデルの予測精度を評価します。トレーニングデータとテストデータの分割は、モデルの性能を正しく評価するために重要な役割を果たします。
トレーニングデータとテストデータの分割により、モデルの性能を正確に評価することができます。ただし、トレーニングデータに偏りがある場合、モデルの性能が過剰に評価される可能性があるため、注意が必要です。そのため、データの前処理や特徴量エンジニアリングなど、適切な手法を用いてデータを整形することが重要です。
シードの固定
シード(seed)とは、ランダムな値を生成するアルゴリズムにおいて、再現性を確保するためのパラメータです。シードを固定することで、ランダムな結果が再現できるため、モデルの評価やハイパーパラメータの調整などにおいて、正確な評価を行うことができます。
シードを固定する方法は、以下のようになります。
import numpy as np
# シードを固定する
np.random.seed(0)このように、numpyライブラリのrandom.seed()メソッドを使用してシードを固定することができます。ただし、シードを固定することで、モデルの性能が安定する反面、最適なハイパーパラメータを見つけるための範囲が狭くなる可能性があるため、注意が必要です。
シードの固定は、機械学習モデルの開発やデータ分析において非常に重要であり、再現性を高めるためには積極的に取り入れることが推奨されます。
early_stopping
Early stopping(早期終了)とは、機械学習モデルの学習中に、過学習を防ぐために、学習を途中で終了させる方法の一つです。早期終了を行うことで、モデルの汎化性能を向上させることができます。
具体的には、学習中に検証用データセットでの性能を監視し、モデルの性能が最大化した時点で学習を終了する方法です。学習の途中で、検証用データセットでの性能が一定期間改善しなかった場合、学習を終了することで過学習を防ぐことができます。
早期終了を実現するためには、以下のような手法があります。
- 検証用データセットでの性能が最大化した時点で学習を終了する(best iteration)
- 検証用データセットでの性能が一定期間改善しなかった場合、学習を終了する(early stopping)
実装の際には、モデルのライブラリによって異なりますが、以下のようなパラメータの設定が必要です。
- early_stopping_rounds:何回改善しなかったら学習を終了するかを指定するパラメータ
- eval_set:検証用データセットを指定するパラメータ
例えば、XGBoostライブラリを使用して早期終了を行う場合、以下のようなコードを記述します。
import xgboost as xgb
# XGBoostモデルのインスタンスを生成
xgb_model = xgb.XGBRegressor()
# パラメータを設定
params = {'n_estimators': 500, 'max_depth': 4, 'learning_rate': 0.01}
# モデルを学習
xgb_model.fit(X_train, y_train, early_stopping_rounds=10, eval_set=[(X_test, y_test)], verbose=False, **params)
このように、モデルのパラメータにearly_stopping_roundsとeval_setを指定することで、早期終了を実現することができます。
Lesson4:パラメータチューニングしてみよう
LightGBM パラメータチューニング
LightGBMのパラメータチューニングは、モデルの性能を最大化するために非常に重要です。LightGBMは、多数のパラメータがあり、それぞれがモデルの性能に影響を与えるため、最適なパラメータの設定が必要です。
以下は、LightGBMの主要なパラメータと、その説明です。
- boosting_type:ブースティングの種類(gbdt, dart, goss)
- num_leaves:決定木の葉の数
- learning_rate:学習率
- n_estimators:学習回数
- max_depth:決定木の深さの制限
- min_child_weight:1つの葉に必要な最小サンプル数
- subsample:サンプリングするデータの割合
- colsample_bytree:サンプリングする特徴量の割合
- reg_alpha:L1正則化の係数
- reg_lambda:L2正則化の係数
その他の重要なパラメータについて説明します。
- objective:損失関数を指定します。LightGBMは、回帰問題や二値分類問題、多クラス分類問題など、様々な問題に対応しています。目的変数の種類に合わせて適切な損失関数を選択する必要があります。
- max_bin:離散化の際に使用されるビンの数を指定します。ビンの数が多いほど、より詳細な特徴量の表現が可能になりますが、計算量が増加します。
- learning_rate:学習率を指定します。学習率は、各決定木がモデルに対してどれだけの重要度を持つかを調整するパラメータです。値が小さいほど、学習が緩やかになりますが、過学習を抑えることができます。
- num_leaves:1つの決定木の最大の葉の数を指定します。葉の数が多いほど、モデルが複雑になりますが、過学習を引き起こす可能性があります。
パラメータチューニングの一般的な手順は、以下のようになります。
- デフォルトのパラメータでモデルを構築し、性能を確認する。
- パラメータの範囲を設定し、グリッドサーチやランダムサーチを行い、最適なパラメータを探索する。
- 見つかった最適なパラメータを用いて、モデルを構築し、性能を確認する。
- パラメータの微調整を行い、最終的なモデルを構築する。
例えば、以下のようなパラメータチューニングのコードを記述します。
import lightgbm as lgb
from sklearn.model_selection import GridSearchCV
# パラメータの範囲を指定する
param_grid = {
'num_leaves': [31, 63, 127],
'learning_rate': [0.05, 0.1, 0.2],
'n_estimators': [50, 100, 200],
}
# LightGBMモデルを構築する
lgb_model = lgb.LGBMRegressor(random_state=0)
# GridSearchCVで最適なパラメータを探索する
grid_search = GridSearchCV(estimator=lgb_model, param_grid=param_grid, cv=3)
grid_search.fit(X_train, y_train)
# 最適なパラメータでモデルを構築する
lgb_model = lgb.LGBMRegressor(**grid_search.best_params_, random_state=0)
lgb_model.fit(X_train, y_train)このように、GridSearchCVを使用して、指定したパラメータ範囲内で最大なパラメータを探索することができます。また、パラメータの微調整には、ベイズ最適化や遺伝的アルゴリズムなどの手法もあります。
ただし、パラメータチューニングには注意が必要です。過学習を起こさないように、モデルの性能を適切に評価する必要があります。具体的には、交差検証やホールドアウト法などを使用して、汎化性能を評価することが重要です。また、パラメータチューニングは、計算コストが高いため、十分な計算リソースが必要です。
Lesson5:検証について
ホールドアウト検証
ホールドアウト検証は、機械学習モデルの性能を評価するために、教師データを訓練用データと検証用データに分割する手法の1つです。以下は、ホールドアウト検証を行うための手順です。
- データセットを訓練用データと検証用データに分割する。訓練用データはモデルの学習に使用され、検証用データはモデルの性能評価に使用される。
- 訓練用データを使用して機械学習モデルを訓練する。
- 検証用データを使用して、モデルの性能を評価する。評価指標として、平均二乗誤差(Mean Squared Error:MSE)や決定係数(R2 score)などが一般的に使用される。
- 評価指標が十分な性能を示す場合、テストデータを使用してモデルの最終評価を行う。これにより、モデルが未知のデータに対してどの程度正確に予測できるかを評価することができる。
以下は、Pythonを使用したホールドアウト検証の例です。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# データセットの読み込み
X = ...
y = ...
# 訓練用データと検証用データに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 線形回帰モデルを訓練する
model = LinearRegression()
model.fit(X_train, y_train)
# 検証用データを使用してモデルの性能を評価する
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 評価指標を出力する
print('Mean Squared Error:', mse)
print('R2 Score:', r2)
このように、train_test_splitを使用してデータを分割し、訓練用データでモデルを訓練して、検証用データで性能を評価することができます。
交差検証
KFold
交差検証は、機械学習モデルの性能を評価するために、教師データを複数の部分集合に分割し、それぞれを交差させながら訓練・検証を行う手法です。以下は、交差検証を行うための手順です。
- データセットをk個の部分集合に分割する(kは任意の値)。これらの部分集合の1つをテスト用データ、残りを訓練用データとする。
- 訓練用データを使用して機械学習モデルを訓練する。
- テスト用データを使用して、モデルの性能を評価する。評価指標として、平均二乗誤差(Mean Squared Error:MSE)や決定係数(R2 score)などが一般的に使用される。
- ステップ1-3をk回繰り返し、k個の評価指標の平均値を算出する。これにより、モデルの汎化性能を評価することができる。
以下は、Pythonを使用したk分割交差検証の例です。
from sklearn.model_selection import KFold
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# データセットの読み込み
X = ...
y = ...
# k分割交差検証を行う
kf = KFold(n_splits=5, shuffle=True, random_state=0)
mse_scores = []
r2_scores = []
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 線形回帰モデルを訓練する
model = LinearRegression()
model.fit(X_train, y_train)
# テストデータを使用してモデルの性能を評価する
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 評価指標を記録する
mse_scores.append(mse)
r2_scores.append(r2)
# 評価指標の平均値を出力する
print('Mean Squared Error:', np.mean(mse_scores))
print('R2 Score:', np.mean(r2_scores))
このように、KFoldを使用してデータをk個の部分集合に分割し、各部分集合で訓練・検証を行うことができます。
交差検証を行うことにより、モデルの汎化性能をより正確に評価することができます。分割数を増やすことで、より高精度な評価が可能になりますが、それに伴って計算時間が増加するため、適切な分割数を選択する必要があります。また、交差検証を使用してモデルのパラメータのチューニングを行うこともできます。
交差検証(StratifiedKFold)
StratifiedKFoldは、k分割交差検証の一種であり、分類問題においてクラスの比率を維持したまま、データセットをk個の部分集合に分割する手法です。KFoldではランダムにデータを分割するため、各分割におけるクラスの比率が偏ってしまう場合がありますが、StratifiedKFoldを使用することで、各分割においてクラスの比率が近似的に等しくなるようにデータを分割することができます。
以下は、Pythonを使用したStratifiedKFoldの例です。
from sklearn.model_selection import StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# データセットの読み込み
X = ...
y = ...
# StratifiedKFoldを使用してデータを分割する
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)
accuracy_scores = []
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# ロジスティック回帰モデルを訓練する
model = LogisticRegression()
model.fit(X_train, y_train)
# テストデータを使用してモデルの性能を評価する
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
# 正解率を記録する
accuracy_scores.append(accuracy)
# 正解率の平均値を出力する
print('Accuracy:', np.mean(accuracy_scores))
このように、StratifiedKFoldを使用してデータをk個の部分集合に分割し、各部分集合で訓練・検証を行うことができます。クラスの比率を維持することにより、偏った評価が行われることを防ぎ、モデルの性能をより正確に評価することができます。
Lesson6:検証データ作成時の注意
時系列データに関する注意
時系列データは、データの取得順序が重要であり、過去のデータが将来のデータに影響を与えるため、通常の分割方法や交差検証の手法を使用することができません。そのため、時系列データに対しては、以下のような注意点があります。
- データを分割する場合は、時間軸に沿って分割する必要があります。つまり、訓練データとテストデータを時間的な軸で分割することが重要です。
- 時系列データに対しては、通常の交差検証ではなく、時系列に沿ったクロスバリデーションが適切です。時系列に沿ったクロスバリデーションは、訓練データを連続的に分割して複数の部分集合に分け、1つの部分集合をテストデータとして使用する方法です。
- 時系列データの特徴量エンジニアリングには、ラグ特徴量(過去のデータの値)や移動平均など、時系列に特化した特徴量を生成することが重要です。
- 時系列データの場合は、未来の値を予測することが目的であるため、テストデータに含まれる未来のデータを使用してモデルを訓練したり、過去のデータと未来のデータを一緒に使用することはできません。
これらの注意点に注意しながら、時系列データに対して適切な分割方法やモデルの構築方法を選択することが重要です。
Lesson7:アンサンブルしてみよう
アンサンブル学習とは、複数の異なるモデルを組み合わせて予測精度を向上させる手法です。アンサンブル学習には様々な手法がありますが、ここでは代表的な2つの手法について説明します。
-
バギング(ブートストラップ法) バギングは、訓練データからランダムに抽出した部分集合を用いて複数のモデルを訓練し、その結果を平均化して予測結果を出す手法です。訓練データからランダムに抽出することで、複数のモデルが異なるサンプルを学習するため、過学習を防ぐ効果があります。
-
ブースティング ブースティングは、複数の弱い学習器を組み合わせて、より強力な学習器を作り出す手法です。弱い学習器は、簡単なモデルであり、精度が低い場合がありますが、多数の弱い学習器を組み合わせることによって、高い精度を得ることができます。
以下は、Pythonを使用したアンサンブル学習の例です。ここでは、バギングとブースティングの両方を使用して、予測精度を向上させます。
from sklearn.ensemble import BaggingClassifier, AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
# データセットの読み込み
X = ...
y = ...
# バギングによるアンサンブル学習
bagging_model = BaggingClassifier(base_estimator=DecisionTreeClassifier(), n_estimators=10, random_state=0)
bagging_scores = cross_val_score(bagging_model, X, y, cv=5)
# ブースティングによるアンサンブル学習
boosting_model = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(), n_estimators=10, random_state=0)
boosting_scores = cross_val_score(boosting_model, X, y, cv=5)
# 結果の出力
print('Bagging scores:', bagging_scores)
print('Boosting scores:', boosting_scores)
print('Bagging mean score:', np.mean(bagging_scores))
print('Boosting mean score:', np.mean(boosting_scores))このように、バギングやブースティングを使用して、複数の異なるモデルを組み合わせることで、予測精度を向上させることができます。
というわけで、今回は以上です。大変お疲れ様でした。
引き続きで、徐々に発信していきます。
コメントや感想を受け付けています。ちょっとした感想でもいいので嬉しいです。
それでは、以上です。





