


生成AI(特にLLM)を使っていて、こんな経験はありませんか?
「同じ内容を頼んでも、微妙に違う答えが返ってくる」
「たった一文変えただけで、全く別の結果になる」
……そう、実はここにこそ、プロンプトの“本質”があります。
プロンプトとは、単なる入力文ではありません。
それは、**AIの行動原理を決定づける“意図の翻訳装置”**であり、**ユーザーの目的を叶えるための“対話設計そのもの”**なのです。
では、なぜそんなにもプロンプトが重要なのか?
そして、どうすれば意図通りの反応をAIから引き出せるのか?
本記事では、トランスフォーマーの仕組みを土台に、プロンプトがもたらす影響を理論的に解き明かし、そこから導かれる“超実践的な4つのTips”をご紹介します。
- 1 プロンプトが重要な「科学的な理由」
- 2 プロンプト設計におけるおさらい 🔑✨
- 3 トランスフォーマーに“別のAI”を模倣させるプロンプトの力 🤖=🧠?
- 4 仮想ニューラルネットワークという革命的概念 🔬💡
- 5 トランスフォーマーが再現できるAIの条件とは?🧩
- 6 方法の紹介|プロンプトによる仮想ネットワーク再現のステップ 🧠⚙️
- 7 プロンプトで「複雑な関数」はどこまで再現できるのか?📈🧠
- 8 方法の紹介|プロンプト設計に役立つ“5つの実践的ポイント”🧰🧠
- 9 1. プロンプトは「長く詳細に」設計せよ 📝
- 10 2. ノイズを排除せよ|不要な情報は性能を下げる 🚫🧹
- 11 3. 多様なプロンプトで思考の幅を広げる 🌈🧠
- 12 4. マルチエージェント型プロンプトで“異なる思考”を融合する 🧑🏫🧪👩🌾
- 13 結論・まとめ|プロンプトは“言葉で描くAIの頭脳” ✍️🧬
プロンプトが重要な「科学的な理由」
——なぜLLMの出力はプロンプトに支配されるのか?🧬
LLMは「順番通りに考える」AIである
大規模言語モデル(LLM)は、文章を一度に理解するのではなく、「一語ずつ」予測しながら生成していく構造を持っています。
つまり、プロンプトの語順・構文・トーン——そのすべてが、“最初の一歩”として次の言葉を決める鍵になります。
たとえば、
-
「次の文章を要約してください」
-
「あなたはプロの編集者です。以下の文章を要約し、読者に響くように再構成してください」
この2つのプロンプトでは、出力される文章の構造もクオリティも大きく変わるのです。
自己注意機構が「どこに注目すべきか」を決める
LLMの中心にあるのが、**自己注意(Self-Attention)**という仕組みです。
これは、入力された単語同士の関係をリアルタイムに計算し、どの単語にどれだけ「注意」を向けるかを自動で調整する機能。
プロンプトが少し変わるだけで、AIがどこに注目すべきかが変化し、出力も大きく揺れるのです。
まさに、プロンプトはモデルの「意識の方向」を決めるナビゲーターなのです。🧭
プロンプト設計におけるおさらい 🔑✨
それでは、理論的分析を踏まえた上で、実際に活用できる“黄金の4Tips”をご紹介します。
✅ 1:役割を明示せよ(Role Prompting)
「あなたは〇〇の専門家です」と冒頭に指定するだけで、LLMの出力が激変します。
これはプリトレーニング中の学習パターンを呼び起こすテクニックであり、タスクの文脈を明確に設定することができます。
💬 例:
✘「このデータを分析してください」
◎「あなたはデータサイエンティストです。このデータからインサイトを抽出し、ビジネスインパクトを分析してください」
✅ 2:出力フォーマットを設計せよ(Structured Prompting)
「箇条書きで答えて」「JSON形式で返して」など、構造をあらかじめ指定することでLLMは正確な出力を行います。
これはLLMの「次に何が来るか」を予測しやすくするため、誤解が生まれにくくなるのです。
💬 例:
◎「要点を以下の3点で整理してください:①概要 ②根拠 ③提案」
✅ 3:具体性で曖昧さを消せ(Contextual Prompting)
曖昧な質問は、曖昧な答えを返します。
プロンプトは「明確なゴール」「制約条件」「背景情報」があるほど精度が高まります。
💬 例:
✘「マーケティングのアドバイスください」
◎「SaaS企業向けに、30代女性をターゲットとしたInstagram広告戦略を提案してください」
✅ 4:思考プロセスを促せ(Chain-of-Thought Prompting)
「段階を追って考えてください」「理由を挙げながら説明してください」と促すことで、LLMの推論プロセスが活性化します。
これは近年の研究でも、難易度の高いタスクほど効果的であることが示されています。
💬 例:
◎「次の判断を行ってください。まず問題を整理し、次に選択肢を比較し、最後に最も効果的な方法を提案してください」
トランスフォーマーに“別のAI”を模倣させるプロンプトの力 🤖=🧠?
これまで、プロンプトとは「AIへの指示文」であり、「LLMの出力を導く文脈づけ」であるとされてきました。
しかし、それは表面的な理解に過ぎません。
今回の研究が示したのは、**プロンプトとは「別のニューラルネットワークをトランスフォーマーの内部に再構築する装置」**であるという、驚くべき仮説です。
つまり、プロンプトを巧みに設計することで、トランスフォーマーという“器”の中に、まったく別のAI=仮想ニューラルネットワークを立ち上げられるというのです。
この考え方は、これまでのプロンプトエンジニアリングの常識を根本から覆すほどの破壊力を持っています。
仮想ニューラルネットワークという革命的概念 🔬💡
では、どのようにして“別のAI”を再現するのでしょうか?
研究者たちが提唱したのが、「仮想ニューラルネットワーク(Virtual Neural Network)」という概念です。
これは、プロンプトに含まれる単語の意味的ベクトル(word embeddings)と、単語の並び順=位置情報(positional encoding)を巧みに組み合わせることで、トランスフォーマーの中に本物のニューラルネットワークと同等の構造と動作を形成するというもの。
しかもこのプロセスには、追加の学習やファインチューニングは一切不要。
ただプロンプトを工夫するだけで、まったく別のAI構造を生み出せるのです。
この仕組みが意味するのは、「プロンプトは情報のきっかけ」どころか、「プロンプトはAIを再設計するコード」だということ。
トランスフォーマーが再現できるAIの条件とは?🧩
もちろん、トランスフォーマーが再現できるニューラルネットワークには条件があります。
研究によれば、「粗い重み行列(coarse weight matrices)」と呼ばれる、比較的単純な構造を持ったネットワークであれば、プロンプトだけで完全に再現可能であることが判明しました。
この“再現”は数学的にも裏付けられており、たとえばシンプルなReLU関数(正の数をそのまま、負の数をゼロにする関数)を再現するプロンプトも設計されました。
ReLUは、深層学習の中でももっとも基本的な活性化関数のひとつです。
その挙動を、自己注意機構とプロンプトの語順・意味だけで再現できたという事実は、トランスフォーマーの柔軟性を理論的に証明するものと言えるでしょう。
方法の紹介|プロンプトによる仮想ネットワーク再現のステップ 🧠⚙️
以下は、仮想ニューラルネットワークをプロンプトで再構成する際の理論的プロセスです。
-
目標とするニューラルネットワークの構造を定義する
(例:入力層→隠れ層→ReLU→出力層) -
各層の重みをプロンプト内の単語ベクトルで表現
→ 単語の意味が“重み”のように機能 -
層の順序や接続は、単語の配置・順番で調整
→ 単語の並びが“ネットワーク構造”を表す -
自己注意機構が、各単語同士の関係を動的に計算
→ 意味と構造を一体的に処理することで、仮想的なネットワークが構築される
これらはあくまで理論的手法ですが、今後のプロンプト設計における「暗黙のルール」として活用できる可能性を秘めています。
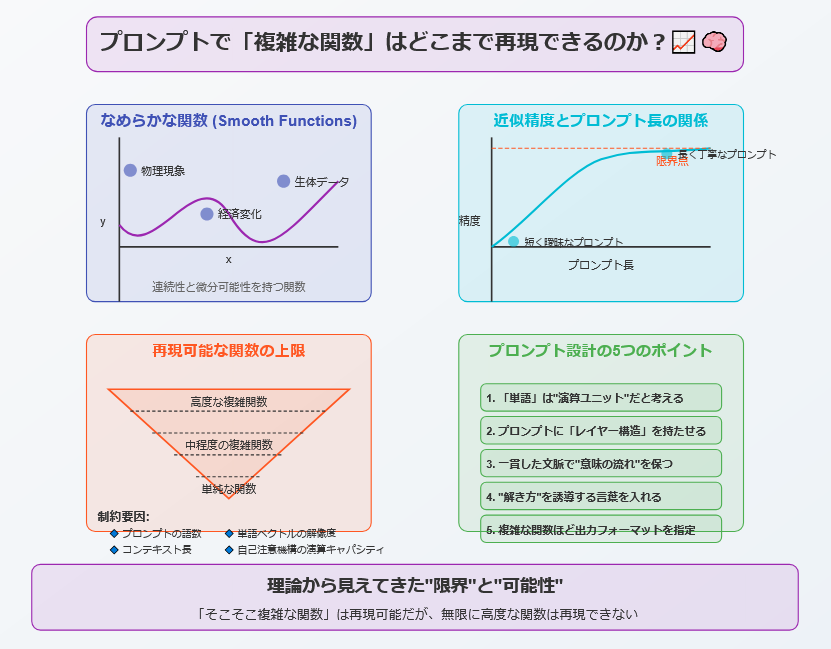
プロンプトで「複雑な関数」はどこまで再現できるのか?📈🧠
——理論から見えてきた“限界”と“可能性”
前章までで、プロンプトによってトランスフォーマーがニューラルネットワークやシンプルな計算関数を模倣できることが明らかになりました。
では、さらに一歩踏み込んで、
「もっと複雑な、非線形の“なめらかな関数”は再現できるのか?」
という問いに答えていきましょう。
「なめらかな関数」=現実世界を記述する鍵🔑
研究者たちが注目したのは、「連続性」と「微分可能性」をもつ、**なめらかな関数(smooth functions)**です。
なぜこのタイプの関数が重要かというと——
✔ 物理現象
✔ 経済の変化曲線
✔ 生体データの挙動
など、私たちの世界に存在する多くの法則や予測モデルは、なめらかな関数として表されるからです。
トランスフォーマーがこれらをプロンプトのみで近似できれば、AIが複雑な現象を“数式レベルで理解・再現”できるということになります。
近似精度をどう評価するか?📏
研究では、プロンプトの「長さ」や「語彙構造」と、再現したい関数の「複雑さ(多項式次数や変化量)」との関係を、数理的に分析しました。
結果として明らかになったのは次のような法則です:
-
プロンプトの長さを増やすほど近似精度は向上する
-
しかし、その向上には明確な“限界点”が存在する
これは、「プロンプト=仮想ニューラルネットワークの設計図」であることを前提とした場合、一定の構造的制約を超えると精度が頭打ちになることを意味します。
🧮 理論的には、「誤差はプロンプト長に対して逆数的に減少する」という式でモデル化されました。
つまり、
-
✨ 長く・丁寧に設計されたプロンプト → 高精度
-
⚠ 短く・曖昧なプロンプト → 誤差が大きくなる
この結果は、日常的なLLMの使用でも“体感的に感じていたこと”を、明確な理論で裏付けたものと言えるでしょう。
トランスフォーマーにできること vs できないこと
理論と実験を通して見えてきたのは、
「プロンプトを工夫すれば、“そこそこ複雑な関数”までは十分に再現可能だが、無限に高度な関数は再現できない」
という現実です。
再現可能な関数の上限は、以下のような要因によって決まります。
-
🔹 プロンプトに含められる語数(トークン数)
-
🔹 モデルの最大コンテキスト長
-
🔹 単語の意味ベクトルが持てる情報の解像度
-
🔹 自己注意機構の演算的なキャパシティ
これにより、どんなに優れたプロンプト設計をしても、近似できる関数の複雑さには“天井”があるという結論に至ったのです。
方法の紹介|プロンプト設計に役立つ“5つの実践的ポイント”🧰🧠
それではいよいよ、研究結果に基づくプロンプト設計の具体的なヒントを解説していきましょう。
これは、LLMを活用して日々の業務や研究を効率化したい方にとって、明日からすぐ使えるノウハウでもあります。
✅ 1.「単語」は“演算ユニット”だと考える
プロンプト内の各単語は、トランスフォーマー内部で“意味”だけでなく、計算の構成要素(ニューロン)として働くと考えましょう。
つまり、「なんとなく語彙を増やす」のではなく、単語ごとに役割(変数、演算、条件分岐)を設計する意識が大切です。
✅ 2. プロンプトに「レイヤー構造」を持たせる
ニューラルネットワークが“層”を重ねるように、プロンプトにも段階的な情報の流れを設けましょう。
💬 例:
Step 1 → 前提となる事実
Step 2 → 問題の構造整理
Step 3 → 考察 or 出力条件
この3層構成は、仮想的な推論ネットワークの骨組みになります。
✅ 3. 一貫した文脈で“意味の流れ”を保つ
トランスフォーマーは、自己注意を用いて文中の関係を推論します。
つまり、文脈の一貫性が高いほど、モデルは“どこに注意を向けるか”を判断しやすくなるのです。
そのため、話題を急に切り替えない・主語や視点を統一するといった設計が、出力の精度に直結します。
✅ 4. “解き方”を誘導する言葉を入れる
「順を追って考えてください」「中間計算を見せながら解いてください」などのChain-of-Thought(思考の連鎖)型プロンプトは、高度な問題に対して非常に有効です。
これは、仮想ネットワーク内での演算ルートを明示的に設計することに等しく、複雑な関数再現に不可欠です。
✅ 5. 複雑な関数ほど「出力フォーマットの指定」が重要
再現する関数が複雑になるほど、どんな形式で答えてほしいかを明示する必要があります。
例:
「関数のグラフイメージを説明しながら、x=0〜5の範囲でステップごとに近似値を算出してください」
これは、**仮想ニューラルネットワークにおける「出力層の設計」**に相当します。
1. プロンプトは「長く詳細に」設計せよ 📝
多くの人が「プロンプトは短く簡潔に」と考えがちですが、
実際は長く丁寧に作られたプロンプトの方が、LLMの性能を最大限に引き出すことがわかっています。
その理由は、プロンプトが長くなることで——
-
トランスフォーマー内に構築される仮想ニューラルネットワークが「多層化」し、
-
より複雑な推論や文脈処理が可能になり、
-
難易度の高いタスクでも正確な出力ができるようになる
という、構造的なブースト効果が働くからです。
ただし、“長ければいい”わけではないという点にも注意が必要です。
💡 ポイント:
-
伝えるべき情報を分かりやすく分割
-
中間ステップや目的を明記
-
無駄な装飾語・曖昧な表現を排除
この設計意識が、“ただの長文”と“性能を引き出すプロンプト”との差を生みます。
2. ノイズを排除せよ|不要な情報は性能を下げる 🚫🧹
プロンプトの質を上げるには、「何を入れるか」以上に「何を削るか」が重要です。
研究では、無関係な単語や曖昧な表現が含まれると、トランスフォーマーが内部で混乱し、仮想ネットワークの精度が低下することが実証されました。
これはまさに、ノイズが信号処理の妨げになるのと同じ原理です。
不要な情報を削除することで、モデルは重要な文脈だけに集中でき、推論の精度とスピードが共に向上します。
💡 ノイズ排除の工夫:
-
曖昧な代名詞(これ・それ)を明確な名詞に置換
-
冗長な接続詞・前置きはカット
-
背景説明は短く要点のみに絞る
3. 多様なプロンプトで思考の幅を広げる 🌈🧠
同じ質問でも、視点や語り口を変えることでLLMの思考回路も変わる。
プロンプトに多様性を持たせることで、モデルが内部に構築するネットワークもより「広がり」のあるものとなり、多角的・創造的なアイデア生成や分析が可能になります。
たとえば、「マーケティング施策を提案して」と一文で聞く代わりに、
-
「消費者心理から考えると?」
-
「競合との差別化の観点では?」
-
「SNSでバズらせるには?」
と、異なるアプローチで複数のプロンプトを投げかければ、各視点ごとに異なる仮想ネットワークが起動し、重層的な出力が得られます。
この手法は、「Diversity of Thought(思考の多様性)」と呼ばれ、実験でも高い効果が確認されています。
4. マルチエージェント型プロンプトで“異なる思考”を融合する 🧑🏫🧪👩🌾
プロンプト設計の中でも高度かつ強力な方法が、「マルチエージェント型設計」です。
これは一つのプロンプトの中に、異なる視点や専門性をもつ“仮想キャラクター”を組み込むというアプローチです。
例:
「この問題について、まず科学者の視点で説明し、その後、教育者の観点で整理し、最後に市民としての立場で提案をまとめてください。」
こうすることで、トランスフォーマー内部では複数の視点に基づく仮想ネットワークが同時に生成され、融合されるため、より深く、バランスの取れた結論が導かれます。
実験では、これにより単一視点では見逃されがちな要素や潜在的リスクが浮かび上がり、回答の質が大幅に向上することが示されています。
結論・まとめ|プロンプトは“言葉で描くAIの頭脳” ✍️🧬
本記事では、プロンプトがLLMの思考・推論・表現力をどう変えるのかについて、最新の理論と実験をもとに紹介しました。
✅ 本記事の要点まとめ
-
プロンプトは、仮想ニューラルネットワークを構築する設計図
-
長く丁寧に設計するほど、LLMの能力は拡張される
-
ノイズを取り除くことで、推論の精度と速度が上がる
-
多様な表現や視点を取り入れることで、回答の幅が広がる
-
マルチエージェント型設計は、複雑な課題に最も有効

